Business continuity plan
Version History
| Annual Review Conducted On | Version Reviewed | Is Change Required (Y/N) | Remarks |
| Version 1.0 | 29-05-2020 | N | Ok |
| Version 1.0 | 18-04-2021 | N | Ok |
| Version 2.0 | 02-02-2022 | N | Ok |
| Version 2.0 | 03-04-2023 | N | Ok |
| Version 2.1 | 26-05-2023 | Y | Ok |
| Version 3.0 | 12-01-2024 | Y | Ok |
Amendment History
| Version | Date | Author (function) | Reviewed by | Approved by | Nature of changes |
| Version 1.0 | 23-05-2020 | Parveen Kumar | DevOps Function | Gaurav Sharma | First Integrated Issue |
| Version 1.0 | 18-04-2021 | Parveen Kumar | DevOps Function | Pankaj Kankar | No Change |
| Version 2.0 | 02-02-2022 | Parveen Kumar | InfoSec function | Arun Kumar | Entity name and Logo Change |
| Version 2.0 | 03-04-2023 | Manhar Sharma | InfoSec function | Ratnesh Ranjan | No Change |
| Version 2.1 | 26-05-2023 | Manhar Sharma | InfoSec function | Ratnesh Ranjan | Soft Drill update |
| Version 3.0 | 12-01-2024 | Manhar Sharma | InfoSec function | Ratnesh Ranjan | Soft Drill & Drill cycle update |
| Version 4.0 | 06-03-2024 | Seraj Ahamad Ansari | InfoSec function | Ratnesh Ranjan | Template updated for enhanced clarity and summary. |
Introduction
The purpose of developing a Business Continuity Plan for FarEye Technologies Pvt. Ltd. (Hereinafter- FarEye) is to ensure the continuation of the business during and following any critical incident that results in disruption to the normal operational capacity.
In the event of a disaster which may disrupt the services of FarEye SaaS services, this document is to be used by the responsible individuals to coordinate the FarEye’s system recovery. The plan is designed to contain, or provide reference to, all the information that might be needed at the time of the recovery. This plan is designed to ensure Business Continuity of FarEye SaaS service offering.
Note This plan is not intended to cover Business Continuity for the operations team of FarEye. |
Business Continuity Management At FarEye
FarEye is committed to its critical business processes and that of its valued customers. The resilience of FarEye to ensure high availability of its services to customers during contemplated business disruptions and thereafter until resumption of Business as Usual. In order to comprehend the viability and readiness of its Business Continuity Management, the exercising of BCP/DR drills through auditable plan, execution, inference and incorporation of lessons learnt are institutionalized. To augment the customized BCP for its adequacy and effectiveness, the framework is aligned to meet the ISO 22301:2012 standards (earlier BS25999).
The objective of this BCP, developed in line with FarEye’s corporate-level BCMS policy, is to prevent & contain potential disruption of services to its operations having an impact on its customers and to associates. It lays down the communication, escalation and actions necessary in the event of an incident or business disruptive situation. It will provide FarEye with a well-researched approach and process to resume services at acceptable service levels within acceptable periods with a view of minimizing the business losses and providing cost-effective measures while providing alternate services.
Business Continuity Planning At FarEye
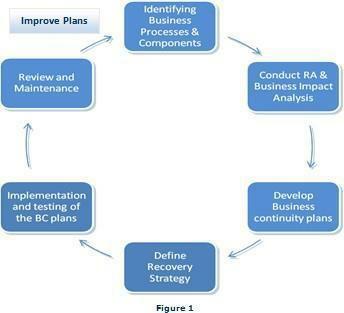
Business Continuity Strategy
This section of the FarEye business continuity plan describes the strategy devised to maintain business continuity in the event of any kind of technical disruption into the FarEye SaaS services. FarEye offerings are technology driven therefore always ensured to automatically recover from a disaster.
Preventive Measures
This subsection covers all the measures taken to ensure the High-Availability of FarEye SaaSservices.
Data Center/ Cloud Infrastructure
FarEye application is hosted on AWS/ Azure cloud which operates in multi-availability zones.
Application Load Balancer
The Application load balancer works as a single point of contact for the clients. It distributes incoming application traffic across multiple application nodes. The application load balancer is configured in high-availability mode to ensure uninterrupted services.
Application
The application nodes are configured in clustering mode to ensure high-availability and to minimize the dependency on one application node. Enough buffer resources have been maintained in all application modes, so it doesn’t get stuck at peak time.
Database
The database is also configured in clustering mode to ensure high - availability. Enough resources have been kept in buffer, so it keeps functioning even in peak time with high load.
Recovery Priority
The strategy is to recover critical services of FarEye on high priority. This can be possible if a recovery strategy has been put into effect by DevOps/Technology teams to provide the recovery services. A list of key services and key customers should be available with the respective Technology Operation team.
The services which are more critical for FarEye and may impact the majority of client and FarEye services,should be prioritized for recovery.
Scope - Critical Process
This document covers all the following areas:
- FarEye Application System
- Database System
- Network Infrastructure
- Server Infrastructure
- Data storage and backup system
- Mobile application
- Integration Platform
- Cloud Infrastructure
Note This document does not cover FarEye operations team and internal function. Please refer to the process specific BCP plan for the same. |
BCP/DR Drill
To test the effectiveness of Business Continuity Plan & scenarios defined in the plan, FarEye has BCP/DR Drill plan in place.
Drill Cycle
There is a half yearly drill cycle that is defined to be carried out. These drills are conducted against the scenarios defined in this document and to check the readiness of BCP/DR plan.
Soft BCP/DR Drill
Soft drills are conducted on a half yearly basis for FarEye application where the last backup of Database & File systems are being restored and tested.
BCP/ DR reports
Drill reports can be shared with the customer upon customer request.
Recovery Procedure Of Critical Processes
The scope includes complete failure scenarios and other failure scenarios in the different business functions for FarEye Application
Complete Application Crash
Though this is the most unlikely scenario for FarEye as we are running our database in cluster mode from multi availability zones. Still, FarEye has requisite Business Continuity Planning and Disaster Recovery Process in place to ensure uninterrupted Services to clients and shall also provide all reasonable assistance to the Clients in its Business Continuity Planning procedures.
In case of a complete database crash. Maximum of 4 (Four) hours (RTO) with recovery point of 24 hours (RPO) — recovered from last transactional log backup, from one or more locations due to any unforeseen event. The TATs and service levels will be suspended during this time.
Declaration of this Scenario will be done by the Emergency Management Team
Other Scenarios
This section lists out the other failure scenarios of application and database services.
First response by Email: support@fareye.com - App support Helpdesk function replies to the emails received from the employees of the client. Query is logged under Fresh Desk, every user on a first come first serve basis. The same query appears in the new list of every associate. Any response received from the SPOCs will be redrafted and forwarded to the employee as resolution. Query is closed in the case management tool (Freshdesk tool) if the complete resolution has been provided to the employee.
Scenario 1: Issue in FarEye application (any specific module is not accessible)Recovery Procedure
Restoring a day-old FarEye application configuration from backup server. BCP Activation Time 15 min
Recovery Time Objective (RTO): 4 Hours
Recovery Point Objective (RPO): 24 Hours
Recovery Location Office:
FarEye, 5th Floor
Lotus Business Park, Plot 6, Noida, 201304
Datacenter: AWS/ Azure Recovery Steps — Summary
Client to be notified immediately by respective SPOCs.
Responsibility
Respective Technology Leads, IT, DevOps, Application Support.
Scenario 2: Issue in Application Database
This scenario takes care of the business outage due to database (may be partial or complete damage) Partial Damage.
All the scenarios covered the partial damage (due to database corruption, deletion, etc.) that impact database comes under this category.
RTO for Partial Damage: 4 Hrs
RPO for partial Damage: 24 Hrs.
Complete Damage
All scenarios covered in “Complete Failure Scenarios” and damage that impact the database come under this category.
RTO for Complete Damage: 4 Hrs.
RPO for Complete Damage: 24 Hrs.
Recovery Location Office:
FarEye, 5th Floor
Lotus Business Park, Plot 6, Noida, 201304
Datacenter: AWS/Azure
Responsibility
Respective Team Leaders, IT, Cloud-Ops, DBA, Application Support.
Notification
| Sr. | Layer | Activity | Responsible | Accountable | Consult | Inform |
1 | EM (Event Management) | Call logging with Support Desk or Freshdesk tool (support@fareye.com) | Support Team | Support Team Manager | Standard operating procedures and Vendor support directory | DevOps - SME, CISO TEAM, Other Impacted Function |
2 | CCP | Notify vendor and internal SME’s | Support Team | Support Team Manager | Process SME | DevOps - SME, CISO TEAM, Other Impacted Function |
3 |
CCP | Notify vendor to initiate supplier continuity plan to provide support and monitor | ||||
4 | CoB | Technology Impact analysis for Support function and Service delivery Unit | Process Team, Information Security Team | Process Lead | DevOps lead- Service notification to all stakeholders | |
5 | CoB | Activate plan – Tech Infra, DevOps, Service Delivery Unit, and supply chain providers | Process Head, CISO | DevOps Manager, Process Manager | DevOps- SME, CISO TEAM, Business Head | |
6 | EM | Event communication | Support Team | Process Lead | DevOps- SME, CISO TEAM, Business head | |
7 | CoB | Business or Support unit business impact assessment and continuity/DR action plan activation | Service Delivery Unit,Information Security Team | Function Head | Support Team | Service Delivery Head, Stakeholders |
8 | EM | Continuity event management ROTA for First Assessment of impacted business units for appropriate and adequate strategy activation requirements in lieu of the IT operations disruption notified by Service Desk | Service Delivery Unit BCL, DevOps lead, CISOTEAM | Service Delivery Head, DevOps Head, CISO TEAM | SLA with vendors. RTO and SLA per business needs RTO aligned to business needs and customer alignment | Service Delivery Head, Function head, Customer communicate on, Associates engaged in the event, stakeholders |
9 | PS | Ensure SMEs are provided with transport and guest house facilities for extended outage periods | Process Manager/ | Admin manager | Email Communication | Process Head, Function head, Admin manager, |
10 | AP | IT infrastructure, damage assessment and Insurance Claims | Location Finance / Admin manager | Location Finance / Admin manager | Process Lead, Admin, Finance | Management |
11 | ES | HVAC at Premises available for operations recovery | LocationADMIN manager | LocationADMIN head | Supply Chain LocationPRAC | Council, Business leaders, LC, MSACF |
15 | CoB | Monitor the SLA agreed Vs SLA delivered for RTO alignment and change recommendations in post event action plan. List of vendors, services, SLA agreed Vs SLA delivered | DevOps, Service Delivery Unit Head, Information Security team | CISO TEAM | BCL Team | CISO and Service Delivery Head |
16 | CoB | Assess BIA, announce plan up to Week 2 and monitor to report every week meeting | BCL, Function heads and Support teams | Function heads | Function head and CISO TEAM | Council, Admin, DevOps, CISO TEAM, Leadership council |
17 | CoB | Recovery and Restoration of operations | Service Delivery Unit, Dev Ops | Service Delivery Unit,Dev Ops | BC Plans, customer priority if any, RTO and/or SLA | Leadership teams |
18 | CoB | Announce Return of business to normal | Function head | Management security and continuity forum chair | Services Delivery Unit head | MSACF Location Council |
| 19 | ATR | After event meeting and action to owner tracking | CISO TEAM | Function head | Support and Business teams | Management |
20 | ATR | Track actions to closure | CISO TEAM | Function head | Support and Business teams | Management |
21 | ATR | Report risk exposures to Management Security Forum | CISO TEAM | Function head | Support and Service Delivery Unit | Management |
22 | ATR | Actions track management security forum continuity improvement plan | CISO TEAM | Function head | Support and Service Delivery Team | Management |
Incident Reporting
The PM/BCL shall ensure that the ADMIN manager / CMT Leader/ERT of the location and or IS team are informed of disruptions of the incident at the earliest. Further, periodic communication will happen to keep all stakeholders posted on the progress.
The PM/BCL shall document and share the Incident report to relevant stakeholders, including the IS team. The incident management process will be followed to ensure prompt alerts and incident handling. Incident escalations will follow the Communication plan mentioned in the BCP.
Incident Report for Emergency Template is available at BMS /Web Qualify.
Incident Response Command Structure And Control Flow
The response ownership during disruption needs effective command structure for execution of planned activities, spot decisions and contingency strategies. Within the scope of the business requirements of the project/ Business Unit, the authority and segregation of accountability is tabulated below to ensure effective governance and planned execution.
| Sr. | Activity | Owner |
| 1 | Reporting of the incident | First respondent |
| 2 | Record as an incident | Support Team |
| 3 | Assessment call to classify the incident in scope of cyber security | SME: DevOps, Service Delivery unit, CISO TEAM, |
| 4 | Severity assessment – Cyber security – IT infrastructure, DevOps to assessment of Applications/Database infrastructure | DevOps, Service Delivery |
| 5 | Severity assessment review – Infrastructure, Data, Apps, | CISO TEAM |
| 6 | Assessment Call (CISO TEAM is the lead assessor of the cyber event call) | CISO TEAM, DevOps stakeholders |
| 7 | Assessment call agenda discussion Environment impact Cyber Infra, DevOps, Apps, Database, Business impact analysis Business operations impact – immediate impacts and RTO brief as per documented BC plans Decision to activate business continuity plans for selective or all |
Admin, DevOps, CISO Team |
| 8 | Notification to stakeholders. | CISO TEAM/DevOps |
| 9 | Business units/ Delivery team/ Function Unit to communicate to partners, customers, teams around impact and readiness with continuity plans and actions summary | Project Lead, Function Head |
| 10 | Monitoring Cyber Event management to closure – End to End | CISO TEAM |
| 11 | IMS records and governance | CISO TEAM |
Communication To Client And Stakeholder
The Communication team will be responsible for informing clients about the disaster and the impact. The best and/or most practical means of contacting all the clients will be used with preference on the following methods (in order):
- E-mail (via corporate email where that system still functions).
- E-mail (via non-corporate or personal email).
- Telephone to employee home phone number.
- Telephone to employee mobile phone number.
The clients will need to be informed of the following:
- Anticipated impact on service offerings.
- Anticipated impact on delivery schedules.
- Anticipated impact on security of client information.
- Anticipated timeline.
Communicating to Partners
After all the clients have been informed about the disaster, the Communication team will be responsible for informing partners of the disaster and the impact.
Crucial partner will be made aware of the disaster situation first. Crucial partners will be e- mailed first then called to ensure that the message has been delivered. Required support should be taken from the partner at time of disaster to restore to the normal operation. All other partners will be contacted only after all crucial partners have been contacted.
Communicating to another Stakeholder
The Communication team will be responsible for informing the remaining stakeholders of the disaster and the impact.
Post Disaster Activities
Once the disaster has been controlled and business resumes back to normal state, following tasks should be carried out as part of Post Disaster Activities:
- Return to normalcy after restoration services
- Lessons Learnt/Key learning’s would be Update in BCP – if required.
- The PM/BCL shall create an incident report stating details of Disaster and impact realized.
- Identify impacted business functionality and recovery mechanisms if any.
- Identify impact on SLA adherence if any.
- Carry out root cause analysis for the disaster and action item for the team if any.
Mandatory Documents Needed
| Sr. | Document |
| 1. | RA & RTP of the Project/ Business Unit |
| 2. | Project specific Installation & configuration procedures |
| 3. | Project management data repository / details |
| 4. | BIA assessment. |
| 5. | Write-up / SOP on each of the Critical Processes declared |
| 6. | BCP/DR drill evidences |
| 8. | Incident Response Procedures for identified threats |
| 9. | Incident Report document |
| 10. | Critical Resource Contact list |
Acronyms And Their Expanded Form
| Sr. | Acronym | Expanded Form |
| 1. | BCM | Business Continuity Management |
| 2. | BIA | Business Impact Analysis |
| 3. | BCP | Business Continuity Plan |
| 4. | DR | Disaster Recovery |
| 5 | RTO | Recovery Time Objective |
| 6. | MAO | Maximum Acceptable Outage |
| 7. | MBCO | Minimum Business Continuity Objective |
| 8. | RA/RTP | Risk Assessment/ Risk Treatment Plan |